목차
- Apache Spark란?
- 왜 Spark를 사용하는가?
- Spark 아키텍처
- Transformation vs Action
- DataFrame & Spark SQL
- GroupBy 내부 작동 방식
1. Apache Spark란?
Apache Spark는 대규모 데이터를 분산 처리하기 위한 통합 분석 엔진입니다.
한 줄 요약: “여러 대의 컴퓨터를 하나의 컴퓨터처럼 사용하여 TB~PB 규모 데이터를 처리하는 엔진”
핵심 특성
| 특성 | 설명 |
|---|---|
| 분산 처리 | 데이터를 여러 노드에 나눠서 병렬 처리 |
| 인메모리 | 중간 결과를 메모리에 보관 → 디스크 I/O 최소화 |
| 통합 엔진 | 배치, 스트리밍, ML, 그래프 처리를 하나의 API로 |
| 다국어 | Python, Scala, Java, R, SQL 지원 |
| Lazy Evaluation | 실행 계획을 먼저 최적화한 뒤 한번에 실행 |
역사
2009 UC Berkeley AMPLab에서 시작
2010 오픈소스 공개
2014 Apache 최상위 프로젝트
2016 Spark 2.0 — DataFrame API, Catalyst Optimizer
2020 Spark 3.0 — Adaptive Query Execution
2023 Spark 3.5 — Spark Connect, 향상된 PySpark
Spark 생태계
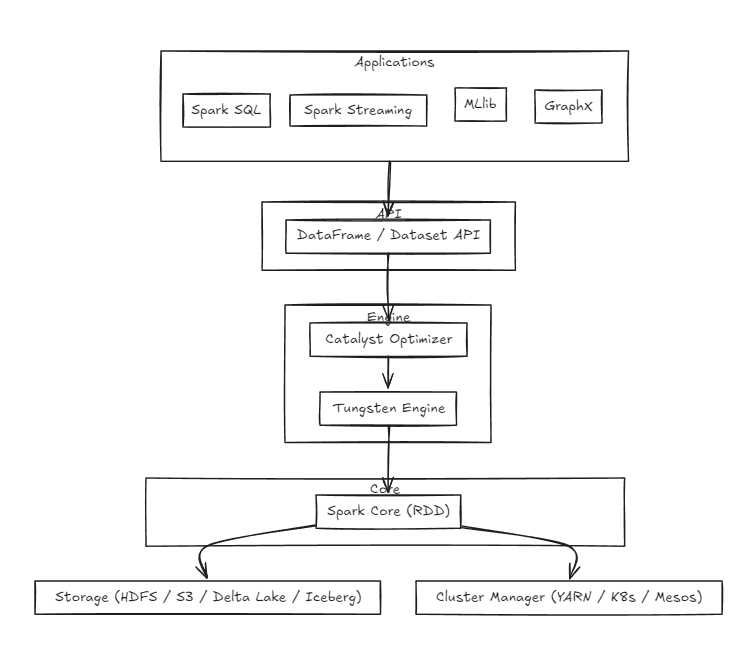
2. 왜 Spark를 사용하는가?
Pandas, Polars, Dask 등이 있는데 왜?
"단일 머신에서 처리할 수 있으면 Pandas/Polars로 충분하다.
그런데 데이터가 단일 머신 메모리를 초과하면?"
도구별 위치 비교
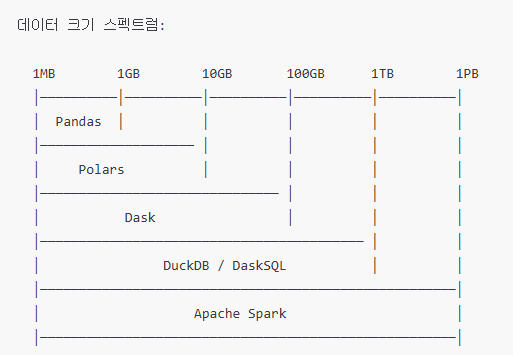
상세 비교
| 항목 | Pandas | Polars | Dask | Spark |
|---|---|---|---|---|
| 처리 규모 | ~수 GB | ~수십 GB | ~수백 GB | TB ~ PB |
| 실행 환경 | 단일 머신 | 단일 머신 | 단일/분산 | 진정한 분산 |
| 언어 | Python | Python/Rust | Python | Python/Scala/Java/SQL |
| 메모리 | 데이터 전체 로드 | 지연 실행 | 청크 단위 | 파티션 단위 분산 |
| 생태계 | 풍부 | 성장 중 | 중간 | 매우 풍부 |
| 클러스터 | 불가 | 불가 | 가능(제한적) | 네이티브 |
| SQL 지원 | 없음 | 있음(제한) | DaskSQL | Spark SQL (완전) |
| 스트리밍 | 없음 | 없음 | 제한적 | Structured Streaming |
| ML | scikit-learn | 없음 | dask-ml | MLlib |
Spark가 지속적으로 쓰이는 5가지 이유
① 진정한 수평 확장 (Horizontal Scaling)
Pandas: 서버 1대 (메모리 64GB) → 64GB 이상 데이터 처리 불가
Spark: 서버 100대 (메모리 64GB × 100) = 6.4TB
필요하면 200대로 늘리면 됨
단순히 노드를 추가하면 처리 능력이 선형으로 증가합니다.
② 클라우드 네이티브 통합
AWS: EMR (Elastic MapReduce)
GCP: Dataproc
Azure: HDInsight / Synapse Analytics
→ 클릭 몇 번으로 Spark 클러스터 생성/삭제
→ 처리할 때만 클러스터 띄우고, 끝나면 삭제 → 비용 절약
모든 주요 클라우드가 매니지드 Spark 서비스를 제공합니다.
③ 배치 + 스트리밍 통합
# 같은 API로 배치도, 스트리밍도 처리
# 배치
df = spark.read.parquet("s3://data/trips/")
# 스트리밍
df = spark.readStream.format("kafka").load()
# 변환 로직은 동일!
result = df.groupBy("zone").count()
④ 검증된 안정성과 생태계
10년 이상 프로덕션 검증
Fortune 500 기업 80% 이상 사용
커뮤니티: 2000+ contributor, 38000+ GitHub stars
연동: Delta Lake, Iceberg, Hudi, Kafka, Cassandra, ...
⑤ SQL 사용자도 접근 가능
-- 데이터 엔지니어가 아니어도 SQL로 TB 데이터 분석 가능
SELECT
zone_name,
COUNT(*) as trips,
AVG(duration) as avg_duration
FROM trips
JOIN zones ON trips.zone_id = zones.id
GROUP BY zone_name
ORDER BY trips DESC
왜 연산이 빠를까?
핵심 1: 인메모리 처리
MapReduce (Hadoop):
Read Disk → Process → Write Disk → Read Disk → Process → Write Disk
═══════════════════════════════════════════════════════════════════
매 단계마다 디스크 I/O → 느림
Spark:
Read Disk → Process (Memory) → Process (Memory) → Write Disk
═════════════════════════════════════════════════════════════
중간 결과를 메모리에 유지 → 디스크 I/O 최소화
→ MapReduce 대비 최대 100배 빠름 (Spark 공식 벤치마크)
핵심 2: Catalyst Optimizer (쿼리 최적화)
사용자가 작성한 코드:
df.filter(col("age") > 30).select("name", "age").filter(col("name") != "unknown")
Catalyst가 최적화한 코드:
1. Predicate Pushdown: 필터를 데이터 읽기 단계로 밀어넣음
2. Filter 합치기: 두 filter를 하나로 병합
3. Column Pruning: 필요한 컬럼만 읽기
→ 실제 실행: 파일에서 name, age만 읽되 age>30 AND name!="unknown"인 것만

핵심 3: Tungsten 엔진 (메모리 최적화)
일반 JVM 객체:
객체 헤더 (16B) + 필드 포인터 + 실제 데이터 → 오버헤드 큼
Tungsten:
Off-heap 메모리에 바이너리 포맷으로 직접 저장
→ GC 부담 감소, 캐시 히트율 향상, 메모리 효율 2~5배
핵심 4: Adaptive Query Execution (AQE) — Spark 3.0+
기존: 실행 전에 통계 기반으로 계획 수립 → 실행
AQE: 실행 도중 실제 데이터 통계를 보고 계획 수정
예: Join 시 한쪽이 예상보다 작으면
Sort Merge Join → Broadcast Join으로 전환
예: 셔플 후 파티션이 너무 작으면
작은 파티션들을 자동으로 합침 (Coalesce)
데이터 크기별 추천 도구

3. Spark 아키텍처
클러스터 구조
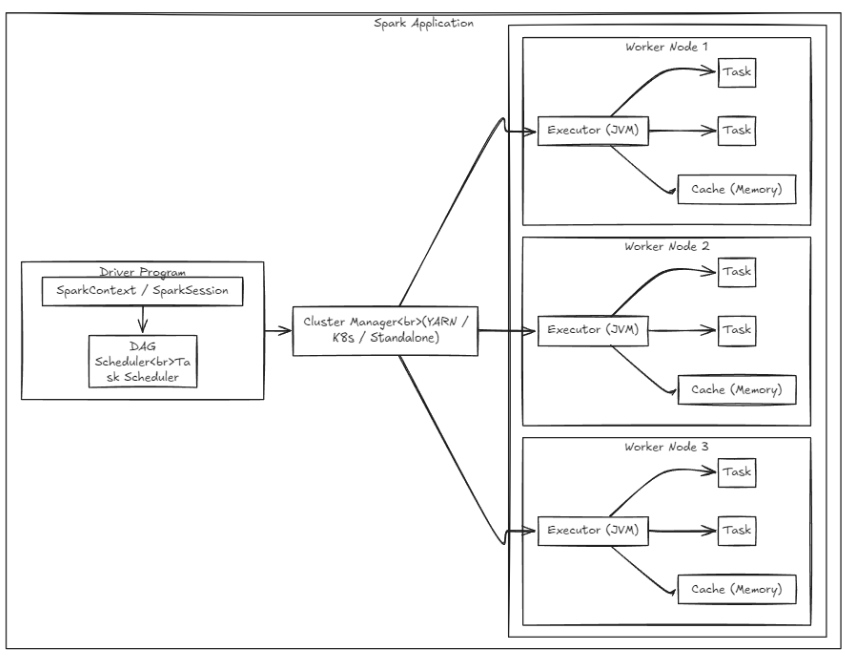
각 구성 요소
| 구성 요소 | 역할 | 비유 |
|---|---|---|
| Driver | 프로그램 진입점. DAG 생성, 태스크 분배, 결과 수집 | 지휘자 |
| SparkSession | Spark 기능 통합 진입점 (Spark 2.0+) | 리모컨 |
| Cluster Manager | 리소스(CPU, 메모리) 할당. YARN, K8s, Standalone | 인사팀 |
| Worker Node | 실제 계산을 수행하는 물리 머신 | 공장 |
| Executor | Worker 위에서 동작하는 JVM 프로세스 | 작업 라인 |
| Task | 하나의 파티션을 처리하는 최소 작업 단위 | 작업자 |
실행 흐름
① spark.read.parquet("...") # Driver: 논리 계획 생성
② .filter(col("age") > 30) # Driver: 논리 계획에 추가
③ .groupBy("dept").count() # Driver: 논리 계획에 추가
④ .show() # Action! Catalyst 최적화 시작
│
▼
⑤ Catalyst Optimizer # 논리 → 물리 계획 변환
│
▼
⑥ DAG Scheduler # Stage 분할 (셔플 경계)
│
▼
⑦ Task Scheduler # 각 Executor에 태스크 배정
│
▼
⑧ Executor에서 병렬 실행 # 결과 → Driver로 반환
Job → Stage → Task 계층
Job (Action 하나 = Job 하나)
│
├─ Stage 0 (Shuffle 이전)
│ ├─ Task 0 (Partition 0: read + filter)
│ ├─ Task 1 (Partition 1: read + filter)
│ └─ Task 2 (Partition 2: read + filter)
│
│ ── Shuffle (데이터 재분배) ──
│
└─ Stage 1 (Shuffle 이후)
├─ Task 0 (부서A 집계)
├─ Task 1 (부서B 집계)
└─ Task 2 (부서C 집계)
Stage 분할 기준: 셔플(데이터 재분배)이 필요한 시점에서 끊김
groupBy,join,repartition,distinct→ 새 Stage
Deploy Mode: Client vs Cluster
Client Mode (개발/테스트):
Driver가 제출한 머신에서 실행 → 로그를 바로 볼 수 있음
[내 노트북] ← Driver 여기서 실행
│
▼
[Cluster]
├─ Executor 1
├─ Executor 2
└─ Executor 3
Cluster Mode (프로덕션):
Driver가 클러스터 내부에서 실행 → 안정적, 제출 머신과 독립
[내 노트북] → spark-submit 제출 후 끊어도 OK
│
▼
[Cluster]
├─ Driver (클러스터 노드에서 실행)
├─ Executor 1
├─ Executor 2
└─ Executor 3
RDD vs DataFrame
RDD (Resilient Distributed Dataset)
# RDD 방식 (저수준)
rdd = sc.textFile("data.csv")
rdd = rdd.map(lambda line: line.split(","))
rdd = rdd.filter(lambda x: int(x[2]) > 30)
rdd = rdd.map(lambda x: (x[3], 1))
rdd = rdd.reduceByKey(lambda a, b: a + b)
rdd.collect()
- Spark의 원래 데이터 추상화 (2011~)
- Java 객체로 저장 → GC 부담, 메모리 비효율
- 최적화 불가 — Spark가 내부 구조를 모름
DataFrame (구조화된 데이터)
# DataFrame 방식 (고수준)
df = spark.read.option("header", "true").csv("data.csv")
df = df.filter(col("age") > 30)
result = df.groupBy("department").count()
result.show()
- 스키마가 있는 분산 테이블 (2015~, Spark 1.3)
- Catalyst Optimizer가 자동 최적화
- Tungsten 엔진으로 바이너리 메모리 관리
- SQL로도 동일하게 표현 가능
비교
| 항목 | RDD | DataFrame |
|---|---|---|
| 추상화 수준 | 낮음 (람다 함수) | 높음 (컬럼 연산) |
| 스키마 | 없음 (비구조화) | 있음 (구조화) |
| 최적화 | 수동 (개발자 책임) | Catalyst 자동 최적화 |
| 메모리 | Java 객체 → 비효율 | Tungsten 바이너리 → 효율 |
| 타입 안전 | 컴파일 타임 | 런타임 |
| 언어 성능 | Scala >> Python | Scala ≈ Python (같은 실행 계획) |
| SQL 통합 | 불가 | 완벽 통합 |
요즘 RDD를 잘 안 쓰는 이유
이유 1: DataFrame이 더 빠름
─────────────────────────────────────
같은 작업을 RDD vs DataFrame으로 하면
DataFrame이 2~10배 빠름 (Catalyst + Tungsten 덕분)
이유 2: Python에서 성능 차이
─────────────────────────────────────
RDD: Python 객체 → 직렬화 → JVM → 역직렬화 → Python
(매 연산마다 Python ↔ JVM 왕복)
DataFrame: JVM 내부에서 최적화된 코드로 실행
(Python은 실행 계획만 전달, 실제 연산은 JVM)
→ PySpark에서 RDD는 극도로 느림
이유 3: 코드 가독성
─────────────────────────────────────
# RDD (읽기 어려움)
rdd.map(lambda x: (x[3], int(x[2]))) \
.reduceByKey(lambda a,b: a+b)
# DataFrame (읽기 쉬움)
df.groupBy("department").agg(F.sum("salary"))
# SQL (누구나 읽을 수 있음)
SELECT department, SUM(salary) FROM employees GROUP BY department
이유 4: API 통합
─────────────────────────────────────
DataFrame API = Spark SQL = Dataset API (Scala)
모두 같은 Catalyst Optimizer를 거침
→ 어떤 API든 같은 실행 계획, 같은 성능
이유 5: 생태계 지원
─────────────────────────────────────
Delta Lake, Iceberg, Hudi → DataFrame 기반
MLlib → DataFrame 기반 (ML Pipeline)
Structured Streaming → DataFrame 기반
새로운 기능은 모두 DataFrame/Dataset 위에 구축됨
RDD를 아직 쓰는 경우:
- 비구조화 데이터 (바이너리 파일 등) 저수준 처리
- accumulator, broadcast 등 저수준 제어 필요
- 레거시 코드 유지보수
4. Transformation vs Action
Lazy Evaluation (지연 평가)
Spark의 가장 중요한 개념:
"Transformation은 실행 계획만 쌓고, Action이 호출될 때 비로소 실행한다"
# ① Transformation — 아무것도 실행되지 않음 (계획만 쌓임)
df = spark.read.parquet("trips/") # 계획: 파일 읽기
df2 = df.filter(col("age") > 30) # 계획: 필터 추가
df3 = df2.groupBy("dept").count() # 계획: 집계 추가
# 여기까지 0줄도 읽지 않음!
# ② Action — 이 순간 전체 실행 시작!
df3.show() # → Catalyst 최적화 → 실행
왜 Lazy?
이유 1: 최적화 기회
─────────────────
모든 연산을 한번에 보고 최적화할 수 있음
예: filter → select → filter
→ Catalyst가 filter 2개를 합치고, 필요한 컬럼만 읽도록 최적화
이유 2: 불필요한 계산 방지
─────────────────────────
df = heavy_computation()
df.take(5) # 5개만 필요한데 전체를 계산할 필요 없음
# Spark가 알아서 5개만 계산하고 멈춤
Transformation (변환) — Lazy
Narrow Transformation (셔플 없음 — 파티션 내부에서만 처리)
| 연산 | 설명 | 예시 |
|---|---|---|
select() | 컬럼 선택 | df.select("name", "age") |
filter() / where() | 행 필터링 | df.filter(col("age") > 30) |
withColumn() | 컬럼 추가/변경 | df.withColumn("age2", col("age")*2) |
drop() | 컬럼 삭제 | df.drop("temp_col") |
map() | 행 단위 변환 (RDD) | rdd.map(lambda x: x*2) |
flatMap() | 행 → 여러 행 | rdd.flatMap(lambda x: x.split()) |
union() | 두 DF 합치기 | df1.union(df2) |
Narrow: 각 파티션이 독립적으로 처리 (네트워크 통신 없음)
Partition 0 ──filter──▶ Partition 0'
Partition 1 ──filter──▶ Partition 1'
Partition 2 ──filter──▶ Partition 2'
Wide Transformation (셔플 발생 — 데이터 재분배 필요)
| 연산 | 설명 | 예시 |
|---|---|---|
groupBy() | 그룹별 집계 | df.groupBy("dept").count() |
join() | 두 DF 조인 | df1.join(df2, "id") |
repartition() | 파티션 재분배 | df.repartition(24) |
distinct() | 중복 제거 | df.distinct() |
orderBy() / sort() | 정렬 | df.orderBy("age") |
reduceByKey() | 키별 축소 (RDD) | rdd.reduceByKey(lambda a,b: a+b) |
Wide: 파티션 간 데이터 이동 필요 (네트워크 셔플)
Partition 0 ──┐
Partition 1 ──┼── Shuffle ──▶ Partition 0' (dept=Engineering)
Partition 2 ──┘ Partition 1' (dept=Marketing)
Partition 2' (dept=Sales)
Action (실행) — 즉시 실행 트리거
| 연산 | 설명 | 반환 |
|---|---|---|
show() / display() | 상위 N개 출력 | 없음 (콘솔 출력) |
count() | 행 수 | 정수 |
collect() | 전체 데이터를 Driver로 | 리스트 (⚠️ 대용량 주의) |
take(n) / head(n) | 상위 N개 | 리스트 |
first() | 첫 번째 행 | Row |
write.parquet() | 파일 저장 | 없음 |
foreach() | 각 행에 함수 적용 | 없음 |
reduce() | 축소 연산 | 값 |
toPandas() | Pandas DF로 변환 | pandas.DataFrame |
전체 흐름 예시
# ── Transformations (Lazy — 계획만 쌓임) ──────────────
df = spark.read.parquet("trips/") # T: 파일 읽기 계획
df2 = df.filter(col("duration") > 0) # T: Narrow (필터)
df3 = df2.withColumn( # T: Narrow (컬럼 추가)
"hour", F.hour("pickup_datetime")
)
df4 = df3.groupBy("hour").agg( # T: Wide (셔플!)
F.count("*").alias("trips"),
F.avg("duration").alias("avg_duration")
)
df5 = df4.orderBy("hour") # T: Wide (정렬!)
# ── Action (실행 트리거!) ─────────────────────────────
df5.show() # A: 지금 실행!
# 실행 순서:
# Stage 0: read → filter → withColumn (Narrow, 셔플 없음)
# ── Shuffle ──
# Stage 1: groupBy 집계
# ── Shuffle ──
# Stage 2: orderBy 정렬 → show 출력
실행 계획 확인
# 논리 + 물리 실행 계획 확인
df5.explain(True)
# 출력 예시:
# == Parsed Logical Plan ==
# Sort [hour ASC]
# +- Aggregate [hour], [hour, count(1) AS trips, avg(duration) AS avg_duration]
# +- Project [*, hour(pickup_datetime) AS hour]
# +- Filter (duration > 0)
# +- Relation [parquet] trips/
#
# == Optimized Logical Plan ==
# Sort [hour ASC]
# +- Aggregate [hour], [...]
# +- Project [pickup_datetime, duration, hour(pickup_datetime) AS hour] ← Column Pruning!
# +- Filter (isnotnull(duration) AND (duration > 0)) ← Predicate Pushdown!
# +- Relation [parquet] trips/
5. DataFrame & Spark SQL
Spark SQL이란?
DataFrame 연산을 SQL 문법으로 작성할 수 있게 하는 모듈입니다.
DataFrame API와 100% 동일한 Catalyst Optimizer를 거치므로 성능 차이가 없습니다.
# DataFrame API
result = df.filter(col("age") > 30) \
.groupBy("department") \
.agg(F.avg("salary").alias("avg_salary")) \
.orderBy(F.desc("avg_salary"))
# Spark SQL — 완전히 동일한 실행 계획, 동일한 성능
df.createOrReplaceTempView("employees")
result = spark.sql("""
SELECT department, AVG(salary) AS avg_salary
FROM employees
WHERE age > 30
GROUP BY department
ORDER BY avg_salary DESC
""")
어떨 때 Spark SQL을 쓰는가?
| 상황 | 추천 | 이유 |
|---|---|---|
| SQL에 익숙한 분석가와 협업 | Spark SQL | SQL은 보편적 언어 |
| 복잡한 조인/서브쿼리 | Spark SQL | SQL이 더 읽기 쉬운 경우 多 |
| 동적 컬럼 처리, UDF | DataFrame API | Python 코드가 유연 |
| ML 파이프라인 | DataFrame API | MLlib가 DataFrame 기반 |
| 기존 SQL 자산 활용 | Spark SQL | 기존 쿼리 재사용 |
| ETL 파이프라인 (혼합) | 둘 다 혼용 | 상황에 맞게 선택 |
현업에서 Spark SQL 쓰는 파이프라인 사례
Case 1: 데이터 웨어하우스 ETL
# Bronze → Silver → Gold 를 Spark SQL로 처리
# 장점: SQL을 아는 누구나 파이프라인 이해/수정 가능
# Silver 정제
spark.sql("""
CREATE OR REPLACE TABLE silver.trips AS
SELECT
CAST(pickup_datetime AS TIMESTAMP) AS pickup_dt,
CAST(dropoff_datetime AS TIMESTAMP) AS dropoff_dt,
CAST(PULocationID AS INT) AS pickup_zone_id,
CAST(DOLocationID AS INT) AS dropoff_zone_id,
TIMESTAMPDIFF(MINUTE, pickup_datetime, dropoff_datetime) AS duration_min
FROM bronze.raw_trips
WHERE pickup_datetime IS NOT NULL
""")
# Gold 집계
spark.sql("""
CREATE OR REPLACE TABLE gold.daily_summary AS
SELECT
DATE(pickup_dt) AS trip_date,
z.zone_name,
COUNT(*) AS total_trips,
AVG(duration_min) AS avg_duration
FROM silver.trips t
JOIN silver.zones z ON t.pickup_zone_id = z.zone_id
GROUP BY 1, 2
""")
Case 2: Databricks / EMR 팀 협업
데이터 엔지니어: Python + DataFrame API로 파이프라인 구축
데이터 분석가: Spark SQL로 노트북에서 쿼리
ML 엔지니어: DataFrame API + MLlib
→ 같은 데이터, 같은 엔진, 다른 인터페이스
Case 3: SQL 기반 스케줄링 파이프라인
# Airflow에서 Spark SQL 실행
from airflow.providers.apache.spark.operators.spark_sql import SparkSqlOperator
task = SparkSqlOperator(
task_id="daily_aggregation",
sql="""
INSERT OVERWRITE TABLE gold.daily_revenue
SELECT DATE(order_date), SUM(amount)
FROM silver.orders
WHERE order_date = '{{ ds }}'
GROUP BY 1
""",
master="yarn",
conn_id="spark_default"
)
DataFrame API vs Spark SQL 혼합 사용 (실전 패턴)
# 읽기: DataFrame API
raw_df = spark.read.parquet("s3://bucket/raw/trips/")
# 뷰 등록
raw_df.createOrReplaceTempView("raw_trips")
# 정제: Spark SQL (복잡한 조인/윈도우 함수는 SQL이 편함)
cleaned = spark.sql("""
SELECT *,
ROW_NUMBER() OVER (PARTITION BY trip_id ORDER BY updated_at DESC) AS rn
FROM raw_trips
QUALIFY rn = 1 -- 중복 제거
""")
# 후처리: DataFrame API (동적 로직은 Python이 편함)
for col_name in nullable_columns:
cleaned = cleaned.fillna({col_name: default_values[col_name]})
# 저장: DataFrame API
cleaned.write.mode("overwrite").parquet("s3://bucket/silver/trips/")
6. GroupBy 내부 작동 방식
기본 원리
groupBy는 2단계로 동작합니다:
단계 1: Map-side (Partial) Aggregation — 로컬에서 먼저 집계
단계 2: Reduce-side (Final) Aggregation — 셔플 후 최종 집계
구체적 흐름
df.groupBy("department").agg(F.count("*").alias("cnt"), F.sum("salary").alias("total"))
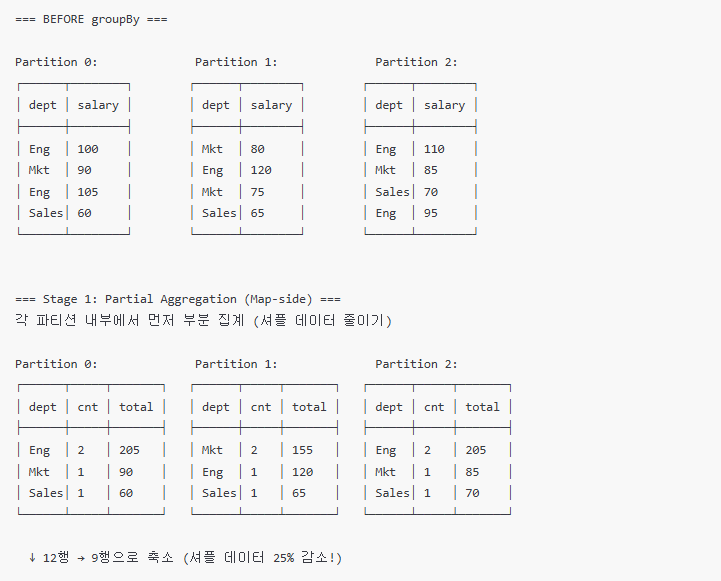


GroupBy 최적화 포인트
① Partial Aggregation 효과
Without Partial Agg:
12행 셔플 → 네트워크 전송 12행
With Partial Agg:
9행 셔플 → 네트워크 전송 9행 (25% 감소)
실제 데이터 (수억 행):
Without: 1억 행 셔플
With: 1만 행 셔플 (그룹 수만큼만!)
→ 셔플 데이터 99.99% 감소!
② 데이터 스큐 문제
문제: 특정 키에 데이터가 몰림
dept="Eng" → 900만 행 → Reduce 파티션 0: 혼자서 900만 행 처리 (병목!)
dept="Mkt" → 50만 행
dept="Sales"→ 50만 행
해결 방법:
방법 1: Salting (키에 랜덤 값 추가)
──────────────────────────────────
df = df.withColumn("salt", F.concat(col("dept"), F.lit("_"), (F.rand()*10).cast("int")))
# "Eng" → "Eng_0", "Eng_1", ..., "Eng_9"
# 900만 행이 10개 파티션으로 분산!
agg1 = df.groupBy("salt").agg(F.sum("salary")) # 분산 집계
agg2 = agg1.withColumn("dept", F.split(col("salt"), "_")[0]) \
.groupBy("dept").agg(F.sum("sum(salary)")) # 최종 합산
방법 2: AQE (Spark 3.0+) 자동 처리
──────────────────────────────────
spark.conf.set("spark.sql.adaptive.enabled", "true")
spark.conf.set("spark.sql.adaptive.skewJoin.enabled", "true")
# Spark가 런타임에 스큐를 감지하고 자동으로 파티션 분할
③ GroupBy + Join (Shuffle 최소화)
# 안 좋은 패턴: groupBy 후 join → 셔플 2번
grouped = trips.groupBy("zone_id").count()
result = grouped.join(zones, "zone_id") # 셔플 2번
# 좋은 패턴: broadcast join → 셔플 1번
from pyspark.sql.functions import broadcast
grouped = trips.groupBy("zone_id").count()
result = grouped.join(broadcast(zones), "zone_id") # 셔플 1번 (zones를 각 노드에 복사)
Broadcast Join 조건:
작은 테이블 < spark.sql.autoBroadcastJoinThreshold (기본 10MB)
→ 자동으로 Broadcast Join 선택
수동 힌트:
SELECT /*+ BROADCAST(zones) */ ...
FROM trips JOIN zones ON trips.zone_id = zones.zone_id
GroupBy Sort-based vs Hash-based
Spark는 기본적으로 Sort-based Aggregation 사용:
1. 같은 키를 가진 데이터를 셔플로 모음
2. 키로 정렬
3. 순차적으로 스캔하며 집계
장점: 메모리 효율 (전체 데이터를 메모리에 올릴 필요 없음)
단점: 정렬 비용
Hash-based는 RDD의 reduceByKey 등에서 사용:
1. 해시 테이블에 키별로 집계
장점: 정렬 없이 빠름
단점: 메모리에 해시 테이블 유지 필요
부록: Spark 설정 치트시트
# 메모리 설정
spark.conf.set("spark.executor.memory", "4g")
spark.conf.set("spark.driver.memory", "2g")
# 셔플 파티션 수 (groupBy 등 셔플 후 파티션 수)
spark.conf.set("spark.sql.shuffle.partitions", "200") # 기본 200
# AQE 활성화 (Spark 3.0+)
spark.conf.set("spark.sql.adaptive.enabled", "true")
spark.conf.set("spark.sql.adaptive.coalescePartitions.enabled", "true")
# Broadcast Join 임계값
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", "10485760") # 10MB
# 동적 파티션 pruning
spark.conf.set("spark.sql.optimizer.dynamicPartitionPruning.enabled", "true")